The myth of more staff: why throwing people at long queues doesn't work
Hiring more staff feels like the obvious fix for long queues—but it often doesn’t work. Learn why queueing systems hit diminishing returns, and what smarter alternatives look like.
When the line grows long, the first instinct is often the most obvious:
We need more people.
From hospitals to call centers to airport security, it’s the go-to reaction: staff up, clear the backlog, problem solved. But in many cases, it doesn’t actually solve the problem—at least, not in the way we think.
Thanks for reading The Queue Report! Subscribe for free to receive new posts and support my work.
And in some cases, it barely makes a dent at all.
More isn’t always better (after a point)
At low staffing levels, adding more people can make a dramatic difference.
Doubling the number of tellers at a bank from one to two, for instance, can drastically reduce the length of the line and individual wait times. However, this impact lessens significantly as staffing increases. Imagine a scenario where you already have ten support agents handling customer inquiries. Adding an eleventh agent might only shave off a few seconds from the average wait time. This is because as you add more staff, the likelihood of individual agents being idle during quieter periods increases. The benefit of each additional hire diminishes because they are not constantly engaged in serving customers.
Why does that happen? Because queueing systems don’t scale linearly. And human demand is messy—bursty, variable, and unpredictable.
💡 In queueing theory, this is called diminishing returns.
In practice, it’s the difference between “efficient” and “expensive but ineffective.”
⏳ As we showed in this article, long waits don’t just frustrate users—they impact conversions, loyalty, and operational cost. Reducing them is critical, but the solution isn’t always more people.
The problem with intuition
Humans are wired to think linearly: twice the work needs twice the staff, right?
But queues don’t behave that way—especially when demand is bursty and service times vary. That is where models like Erlang-C come in.
Originally developed for telephone exchanges and now used in call centers, helpdesks, and service desks, the Erlang-C formula helps estimate performance measures such as:
How long people will wait
How many staff are needed to keep wait times reasonable
And how performance changes as load increases
From this model, we get a surprisingly useful shortcut…
The Square Root Staffing Rule: a smarter heuristic
This principle isn’t new. The Erlang-C model, used widely in call centers and customer service, gave rise to a famous rule of thumb:
💡 To keep delays stable as demand grows, you don’t need to add one staff member per extra user.
You only need to add staff at a rate proportional to the square root of that growth.
Due to not every additional customer arriving at the exact same moment, the increase in required staff scales at a lower rate than the increase in customers to maintain a similar service level.
That means:
Going from 100 to 121 customers doesn’t require 21 more staff.
You can often maintain performance by adding just a few.
But this also means the reverse:
If you’re already operating at high capacity, adding one more agent might not change much—especially under variable demand.
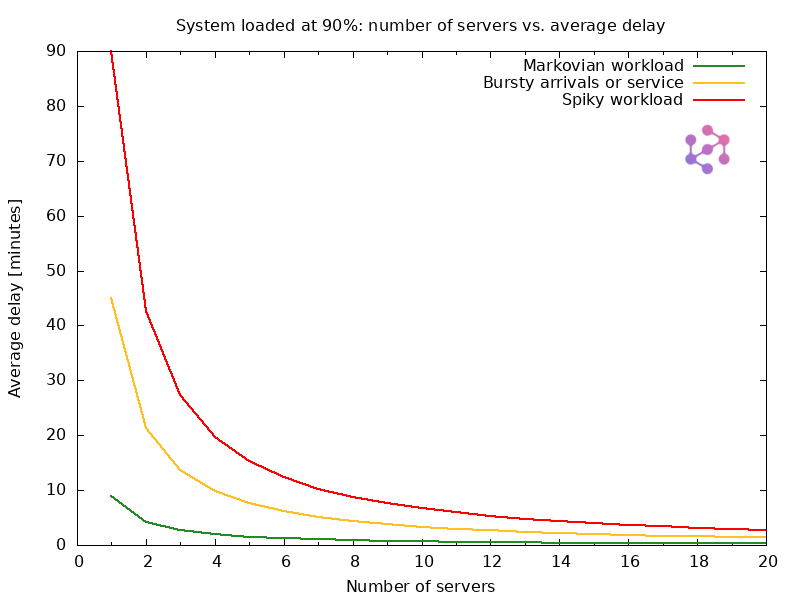
Figure 1 shows the average waiting time in queue for a system operating at a constant 90% utilization.
To keep utilization fixed, we scale the arrival rate in direct proportion to the number of servers — meaning that as we double the number of servers, we also double the incoming load. At first glance, that might seem fair: more people, more capacity. But queues don’t work that way.
Despite the load being constant in percentage terms, the actual waiting time doesn’t scale linearly. The first few servers dramatically reduce delay, but each additional one contributes less and less — a clear example of diminishing returns in queueing systems.
This illustrates a key principle:
⚠️ More staff ≠ proportionally better performance — especially at high utilization levels.
Figure 1 - Average waiting time decreases as more staff are added, but gains shrink rapidly. At 90% utilization, increasing from 2 to 4 staff slashes delays—but going from 19 to 20 has barely any effect. This is the law of diminishing returns in action.
While this chart shows average wait times in minutes, the exact values depend on system-specific parameters like service time. If your average service takes 30 minutes instead of 1, the delays would scale accordingly. But the trend remains the same: adding servers reduces delays, especially when you’re understaffed—but with diminishing returns as capacity grows.
🧠 Why pooling resources matters
Pooling resources—serving requests from a shared queue rather than splitting them across independent lines—is a well-known strategy in queueing theory. It reduces delay, improves stability, and increases resilience under bursty or unpredictable demand.
This isn’t new: it is a fundamental principle, frequently cited in both theory and practice. A widely referenced explainer by Harchol-Balter et al., 2021 summarizes it simply: for a fixed load, increasing the number of servers in a pooled configuration can reduce delay multiplicatively—without adding more capacity.
This principle is so powerful, in fact, that a single shared queue with 10 agents operating at 95% utilization will typically yield shorter average wait times than a single-agent queue at just 70%. In queueing theory terms, the effect of pooling dominates the benefits of simply reducing load—especially under variable or bursty demand.
(And while we use the word “servers” in the queueing theory sense, this applies equally to real people: cashiers, agents, nurses—any resource that serves requests.)
We introduced this concept visually in our article “Stuck in Port”, contrasting multiple parallel lines with a single queue feeding multiple servers—a structure that not only feels fairer, but performs better.
Yet in real-world environments—like grocery stores or government offices—practical constraints such as space, customer segmentation, or UI considerations often prevent this kind of pooling.
Still, whenever possible, pooling is your friend:
It leads to shorter wait times.
It makes systems more resilient to spikes.
It simplifies scheduling and load balancing.
If you are forced to split queues—for customer tiers, task types, or UX reasons—then strategic modeling becomes even more important to prevent bottlenecks and inefficiencies.
💡 Need help modeling staffing impact or reducing queue times without overstaffing? Let’s talk.
Why more staff isn’t always the answer
There are four reasons why throwing people at queues eventually stops working:
📊 Variability overwhelms capacity
If user demand isn’t reasonably steady, adding one person doesn’t fix a spike—it just shifts the bottleneck.
The chart above illustrates this well. Even at the same 90% utilization, systems exposed to more variable (or “spiky”) traffic experience significantly higher delays. And while adding servers helps, the impact of variability remains — especially when the number of servers is small.
For example, in a call center with predictable call volumes, adding one agent might meaningfully reduce wait times. But if there is a lunch-hour spike of 20 calls in 15 minutes, a single extra agent doesn’t solve the problem — it just buys a little breathing room before the queue backs up again.
🔧 Coordination overhead
As teams grow, so does complexity. More people doesn’t always mean more throughput. Larger teams can face communication breakdowns, training challenges, and scheduling friction—all of which can undermine efficiency instead of improving it.
💸 Cost-benefit mismatch
Each new staff member comes with fixed costs—salary, benefits, onboarding, and more—but the performance gains diminish. The marginal benefit drops with each hire, while the marginal cost remains constant, leading to inefficient scaling.
💣 Ignoring upstream problems
Many queues aren’t a staffing issue—they’re a system issue. Common culprits include:
Inaccurate forecasting, leading to mismatches between available staff and actual demand, regardless of the total number of employees.
Bad triage, inefficiently directing users to the wrong service channels or agents, causing unnecessary delays.
Inefficient workflows, causing bottlenecks in the service process itself that slow down every interaction.
Misaligned priorities, where low-urgency tasks clog up service for high-priority users.
Throwing more people at these problems won’t help if the system itself is broken.
🤯 Sometimes, it’s not just about performance—it’s about perception. In our article on digital queue frustration, we explore how poorly designed queues lead to confusion, abandonment, and churn—even when the system is technically holding up.
📈 Solving the problem often starts with smarter triage, better forecasting, or intelligent throttling—not just throwing more people at the front line.
📉 Long queues don’t just cost time—they cost trust and revenue.
Instead of solely focusing on adding more people, consider these smarter alternatives:
Smooth demand
Implement appointment systems (common in healthcare and government services), utilize triage to direct users appropriately, and prioritize urgent requests.
Shorten average service time
Invest in better tools and technology (e.g., knowledge base systems for self-service), improve staff training, and automate repetitive tasks to free up agent time.
Postpone low-priority requests
Offer different service level agreements and schedule non-urgent tasks for off-peak hours to better manage workload.
Leverage forecasting and dynamic scheduling
Utilize historical data and seasonal trends to predict demand and employ dynamic scheduling tools to adjust staffing levels in real time based on predicted fluctuations.
🔍 Related insight: Brooks’ Law
While rooted in software engineering, this principle also applies to operations and queueing systems. More people = more coordination, not always more throughput.
The same applies to overloaded queues—more people can add complexity without fixing the core problem. And sometimes, rather than increasing capacity, you may be in the position of reducing load.
In our deep dive on virtual waiting rooms, we explore how gating traffic—rather than endlessly scaling capacity—can lead to more stable, predictable systems. It’s not just for e-commerce; it’s a queueing strategy with wide applications.
⚙️ A smaller, smarter team can often outperform a larger, rigid one—if the system around them is designed well.
Final thoughts: the art of the queue
The next time you hear “just add more people,” pause.
In the world of queueing systems, more isn’t always better. It’s about how you manage demand, prioritize service, and build resilience into the system—not just how many hands you put on deck.
📦 And as we explained in this piece on supply chain queues, even adding more ships or docks doesn’t always fix congestion—it’s about system flow, not just system size.
Thanks for reading The Queue Report! Subscribe for free to receive new posts and support my work.